
Slurm is a combined batch scheduler, billing, and resource manager that uses slurm accounts to allow users with a login to the High Performance Computing clusters to run their jobs for a fee. For many researchers this fee is paid for by the University of Michigan Research Computing Package account. This document describes the process for submitting and running jobs under the Slurm Workload Manager on the current High Performance Computing clusters (Great Lakes, Armis2 and Lighthouse).
The batch scheduler and resource manager work together to run jobs on an HPC cluster.
- WHEN: The batch scheduler, sometimes called a workload manager, is responsible for finding and allocating the resources that fulfill the job’s request at the soonest available time. The time to start the job will be faster if the batch script is written well for what the job will need (i.e. not asking for too many resources).
- HOW WELL: When a job is scheduled to run, the scheduler instructs the resource manager to launch the application(s) across the job’s allocated resources. This is also known as “running the job”. The job will run best if the batch script is configured for what is needed to complete the job (i.e. making sure that the job processes can be completed on what is requested).
- HOW MUCH: When a job has completed, you can check the funds remaining in your account on the Research Management Portal (RMP).
Cluster Basics and Terminology
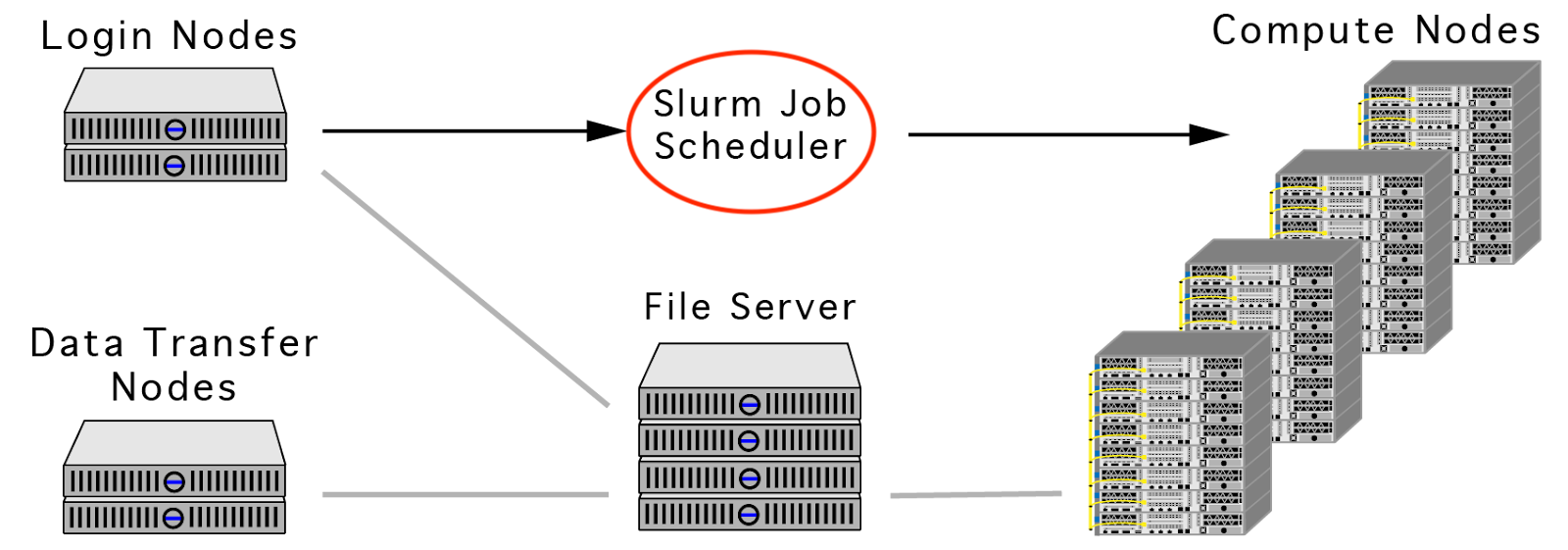
An HPC cluster is made up of a number of compute nodes, each with a complement of processors, memory, and GPUs. The user submits jobs that specify the application(s) they want to run along with a description of the computing resources needed to run the application(s).
Cluster Schematic: The architecture of a High Performance Computing Cluster.
account (relates to Slurm ): A group of users with a chargeable shortcode and optional limits that is configured in slurm to provide a way to run jobs for a fee on a cluster.
batch: Instructions run in a file without user interaction, typically referred to as 'run in batch'
batch script: A text file containing a series of resource specifications, such as the number of nodes, amount of memory, and other requirements needed to run, and commands to be run. This script is submitted to the Slurm workload manager, which schedules and executes the job on available compute nodes within a high-performance computing (HPC) cluster.
core: A processing unit within a computer chip.
CPU: The chip in a node that performs computations.
GPU: A graphics processing unit (GPU) is a specialized processor which can generate computer graphics, but in HPC, designed to accelerate computation-intensive tasks by performing parallel operations, making it ideal for tasks such as simulations, deep learning, and scientific computations.
job: A task or set of tasks, submitted to the cluster scheduler to be executed.
login: Your uniqname. Can also mean to use your login and your level-1 password to gain access to a cluster.
node: A physical machine in a cluster, including login, compute, and transfer nodes
- Login nodes The login nodes are a place where users can login, edit files, view job results and submit new jobs. Login nodes are a shared resource and should not be used to run application workloads. There are limits on the login nodes.
- Head node: The head node is the primary control node that manages the overall operation of the cluster. .
- Data Transfer node: The data transfer node is available for moving data to be accessible to and from the cluster. At ARC, this is done primarily via Globus.
- Compute node: The compute nodes are the computers where jobs are run. To run jobs on the compute nodes, users need to access a head node and schedule their program to be run on the compute nodes once the requested resources are available.
Node Geometry: The physical and logical arrangement of nodes in the cluster are being requested across the available resources on a cluster that need to be optimized for your particular job based on what the job is trying to accomplish. The geometry of these nodes can influence the overall performance, efficiency, and scalability of computational tasks.